The Heart of the Machine & ArXiv Weekly
Participation: Chu Hang, Luo Ruotian, Mei Hongyuan
This week’s important papers include the first research on the world model of Yann LeCun, a Turing Prize winner, and MusicGen, a Meta open source text-generated music model.
Directory:
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
Disentangling Writer and Character Styles for Handwriting Generation
INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models
Reverse Engineering Self-Supervised Learning
VideoComposer: Compositional Video Synthesis with Motion Controllability
Simple and Controllable Music Generation
Arxiv Weekly Radio Station: More Selected Papers of NLP, CV and ML (with Audio)
Paper 1: self-supervised learning from images with a joint-embedding predictive architecture
Authors: Mahmoud Assran et al.
Paper link: https://arxiv.org/pdf/2301.08243.pdf
Abstract: Let AI learn and reason like human beings, which is an important step for artificial intelligence to move towards human intelligence. Yann LeCun, winner of Turing Prize, once proposed a solution of self-monitoring and world model, and now he finally has the first real visual model-I-JEPA. As shown in the following figure, I-JEPA uses a single context block to predict the representations of various target blocks originating from the same image.
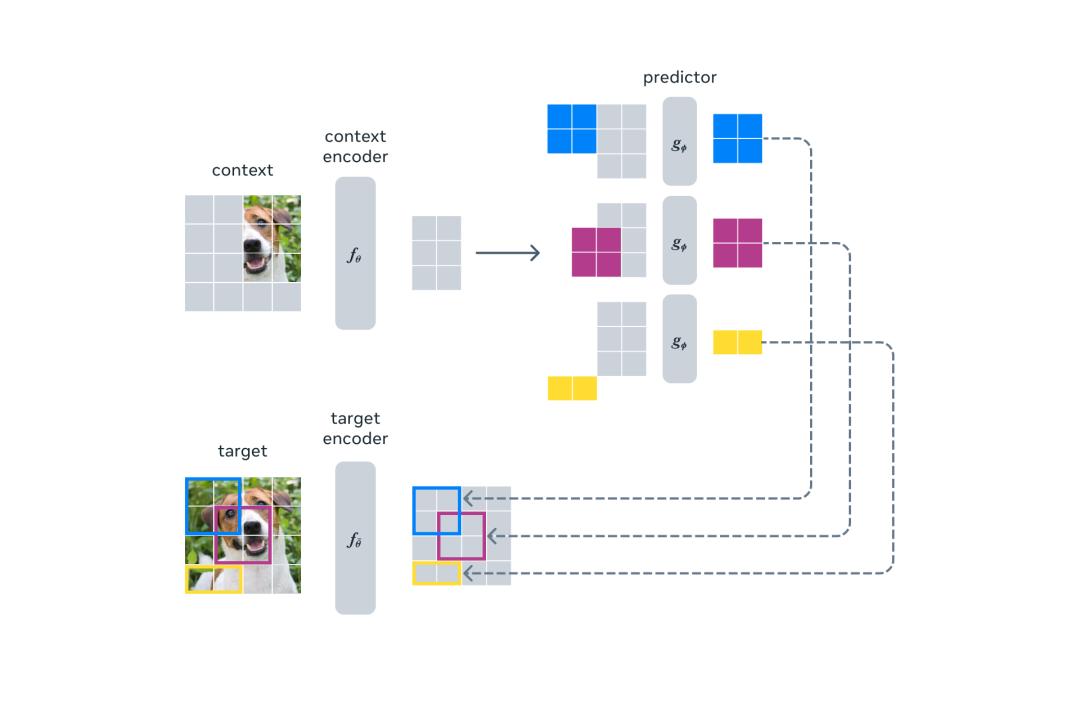
Recommendation: The first study of LeCun world model is coming: self-monitoring vision, learning and reasoning like human beings, which is open source.
Paper 2: Adversarial example does good: preventing painting from different models via Adversarial examples.
Authors: Chumeng Liang et al
Paper link: https://arxiv.org/abs/2302.04578
This paper introduces a paper included in ICML 2023 Oral, which was jointly completed by the Shanghai Key Laboratory of Scalable Computing and Systems, new york University and Queen’s University of Belfast. The joint works of this thesis are Liang Chumeng, who is about to study for a doctorate at the University of Southern California, and Wu Xiaoyu, a graduate student at Shanghai Jiaotong University.

Recommendation: quietly add pixel-level watermark to the picture: the method to prevent AI from "copying" works of art has been found.
Paper 3: Disentangling Writer and Character Styles for Writing Generation
Authors: Gang Dai et al.
Paper link: https://arxiv.org/abs/2303.14736
In this paper, researchers from South China University of Technology, National University of Singapore, Hong Kong Polytechnic University and Pazhou Laboratory jointly put forward an interesting handwritten character generation method, which can copy the user’s writing style only by providing a few reference samples, and then generate arbitrary characters that conform to this style.

Recommendation: AI, which can imitate handwriting, creates a unique font for you and is selected as CVPR 2023.
Paper 4: Instructive Eval: Towards Holistic Evaluation of Instruction-Tuned Large Language Models
Authors: Yew Ken Chia et al.
Paper link: https://arxiv.org/abs/2306.04757
Abstract: Over the years, what is the performance of instruction tuning large language model? This study puts forward a brand-new evaluation suite, which comprehensively evaluates them in solving problems, writing and aligning human values, and the results may exceed your expectations. The researchers provide an overall overview of the open source instruction model in Table 3 below.
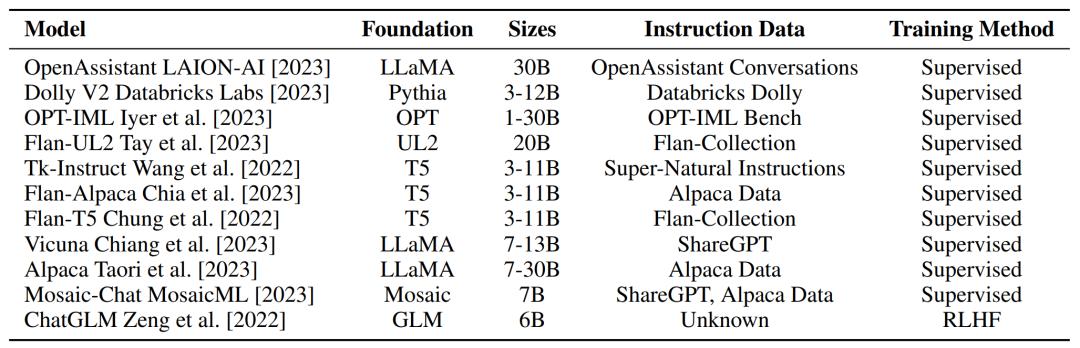
Recommendation: for four years, the basic open source model has not really improved, and the evaluation of the instruction tuning model is amazing.
Paper 5: reverse engineering self-supervised learning
Authors: Ido Ben-Shaul et al.
Paper link: https://arxiv.org/abs/2305.15614v2
Self-supervised learning can use the unsupervised data of auxiliary tasks to mine its own supervision information, and train the network through this constructed supervision information, so as to learn valuable representations for downstream tasks. Recently, many researchers, including Yann LeCun, winner of Turing Prize, published a study, claiming that self-supervised learning was reverse-engineered, so that we could understand the internal behavior of its training process.
In order to intuitively understand SSL training, Figure 1 below shows the embedding space of training samples of the network through UMAP visualization, which includes the situation before and after training and is divided into different levels.
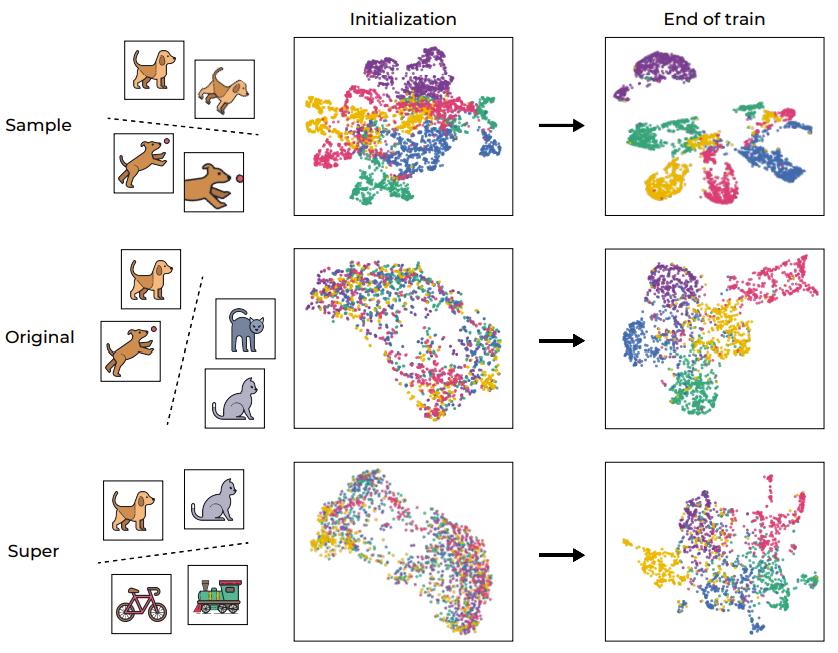
Recommendation: New research achievement of Yann LeCun team: For self-supervised learning reverse engineering, the original clustering is realized in this way.
Paper 6: video composer: comprehensive video synthesis with motion controllability
Authors: Xiang Wang et al
Paper link: https://arxiv.org/abs/2306.02018
Abstract: In the field of AI painting, Composer proposed by Ali and ControlNet proposed by Stanford led the theoretical development of controllable image generation. However, the exploration of controllable video generation in the industry is still in a relatively blank state. Compared with image generation, controllable video is more complicated, because besides the spatial controllability of video content, it also needs to meet the controllability of time dimension. Based on this, the research teams of Alibaba and Ant Group took the lead in making an attempt and put forward VideoComposer, which realizes the controllability of video in both time and space through combined generation paradigm.
In this study, the performance of VideoComposer is directly tested on nine different classic tasks, and satisfactory results are obtained, which proves the universality of VideoComposer.
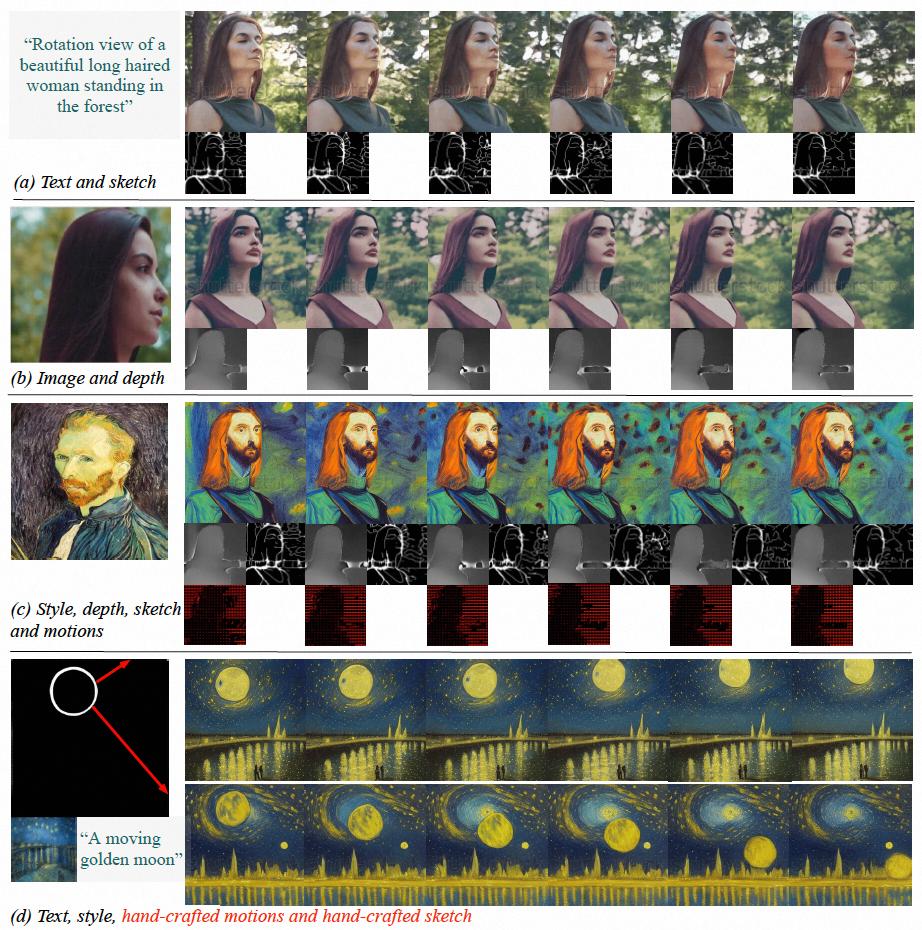
Recommendation: Video generation with controllable time and space has come into reality, and the new work VideoComposer of Ali’s big model is on fire.
Paper 7: simple and controllable music generation
Authors: Jade Copet et al.
Paper link: https://arxiv.org/pdf/2306.05284.pdf
Abstract: At the beginning of the year, Google launched MusicLM, a big model of music generation, and the effect was very good. Some people say that this is more important than the ChatGPT of the fire, which almost solves the problem of music generation. Recently, Meta also launched its own text music generation model, MusicGen, which is free for non-commercial use.
Enter the first two sentences in the lyrics of Jay Chou’s "Qi Li Xiang" as follows: "The sparrow outside the window talks on the telephone pole, and you say this sentence is very summer-like" (in Chinese).
Recommendation: Meta open source text generates a big music model, and we tried it with the lyrics of Qilixiang.
ArXiv Weekly Radiostation
Machine Heart, together with ArXiv Weekly Radiostation initiated by Chu Hang, Luo Ruotian and Mei Hongyuan, selected more important papers this week, including 10 selected papers in NLP, CV and ML fields, and provided an audio abstract introduction. Details are as follows:
The 10 NLP selected papers this week are:
1. Can Large Language Models Infer Causation from Correlation? . (from Bernhard Sch?lkopf)
2. Developing Speech Processing Pipelines for Police Accountability. (from Dan Jurafsky)
3. SqueezeLLM: Dense-and-Sparse Quantization. (from Michael W. Mahoney, Kurt Keutzer)
4. Morphosyntactic probing of multilingual BERT models. (from Noah A. Smith)
5. ChatGPT for Us: Preserving Data Privacy in ChatGPT via Dialogue Text Ambiguation to Expand Mental Health Care Delivery. (from Kai-Wei Chang, Majid Sarrafzadeh)
6. Language models are not naysayers: An analysis of language models on negation benchmarks. (from Timothy Baldwin)
7. Modality Adaption or Regularization? A Case Study on End-to-End Speech Translation. (from Jingbo Zhu)
8. Xiezhi: An Ever-Updating Benchmark for Holistic Domain Knowledge Evaluation. (from Rui Xu)
9. Word sense extension. (from Lei Yu)
10. Instruction Tuned Models are Quick Learners. (from Chitta Baral)
The top 10 CV selected papers this week are:
1. Multi-Modal Classifiers for Open-Vocabulary Object Detection. (from Andrew Zisserman)
2. AVIS: Autonomous Visual Information Seeking with Large Language Models. (from Kai-Wei Chang, Cordelia Schmid)
3. SMC-UDA: Structure-Modal Constraint for Unsupervised Cross-Domain Renal Segmentation. (from Rama Chellappa, Xinbo Gao)
4. Aladdin: Zero-Shot Hallucination of Stylized 3D Assets from Abstract Scene Descriptions. (from Leonidas Guibas)
5. Adding 3D Geometry Control to Diffusion Models. (from Alan Yuille)
6. Compositor: Bottom-up Clustering and Compositing for Robust Part and Object Segmentation. (from Alan Yuille)
7. Teaching AI to Teach: Leveraging Limited Human Salience Data Into Unlimited Saliency-Based Training. (from Kevin Bowyer)
8. Instant Multi-View Head Capture through Learnable Registration. (from Michael J. Black)
9. FlowFormer: A Transformer Architecture and Its Masked Cost Volume Autoencoding for Optical Flow. (from Xiaogang Wang)
10. MOFI: Learning Image Representations from Noisy Entity Annotated Images. (from Jon Shlens)
The 10 ML selected papers this week are:
1. A Comprehensive Survey on Applications of Transformers for Deep Learning Tasks. (from Witold Pedrycz)
2. Inductive Linear Probing for Few-shot Node Classification. (from Huan Liu)
3. Virtual Node Tuning for Few-shot Node Classification. (from Huan Liu)
4. Understanding How Consistency Works in Federated Learning via Stage-wise Relaxed Initialization. (from Dacheng Tao)
5. Extending Kernel PCA through Dualization: Sparsity, Robustness and Fast Algorithms. (from Johan A. K. Suykens)
6. Variational Positive-incentive Noise: How Noise Benefits Models. (from Xuelong Li)
7. Privacy Preserving Bayesian Federated Learning in Heterogeneous Settings. (from Joydeep Ghosh)
8. One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning. (from Eric Xing)
9. Identification of Nonlinear Latent Hierarchical Models. (from Eric Xing)
10. Composing Efficient, Robust Tests for Policy Selection. (from Peter Stone)
? THE END
Please contact Ben WeChat official account for authorization.
Contribute or seek reports: content@jiqizhixin.com.
Original title: "7 Papers & Radios | LeCun World Model is the first attempt; Meta open source text music generation model "
Read the original text